
등장 배경 - 분산 시스템
어떤 데이터를 처리하는 서버가 있다고 생각해보자. 그리고 지금 아슬아슬하게 해당 컴퓨팅 성능의 최대치로 서버가 작동하고 있다고 가정해보자. 만약 처리해야할 데이터의 양이 두배가 된다면 어떻게 할 수 있을까?
일단 먼저, 컴퓨터 성능을 두배로 올리는 방법을 생각해볼 수 있겠다. CPU도 두배 좋은걸로, 램도 두배 많이! 하지만, 두배 좋은 컴퓨터를 만드는 비용은 겨우 두배가 아니다. 아니, 그전에 두배 좋은 CPU가 세상에 존재하지 않을 수도 있다. 제일 좋은 CPU를 쓰고 있다고 업그레이드가 불가능하면 안되잖아!
- 이 방식을 Scale-up 방식이라고 한다.
이대신 보다 저렴한 서버를 수십, 수백대 연결해서 성능을 확장하는 방식을 사용할 수 있겠다. 이러면 가성비 좋은 영역에서 서버를 계속 확장시켜나갈 수 있다.
- 이 방식을 Scale-out 방식이라고 한다.
그런데, 이 과정이 생각만큼 쉽지는 않다. 모든 서버에 데이터가 잘 저장이 되어 있나? 한두개의 서버가 죽어도 데이터가 유지가 되나? 업데이트 쿼리는 어디 서버에 날려야 하지? 읽기 쿼리는 어디 서버에 날려야 하지? 이걸 관리는 무슨 컴퓨터가 하지? 그 컴퓨터는 사양 문제에서 자유로운가? 등등 너무나 많은 문제점이 생길 수 있다. 이를 하나하나 파헤쳐보자.
하둡(Hadoop)이란?
The Apache® Hadoop® project develops open-source software for reliable, scalable, distributed computing.
하둡 공식 사이트 에 들어가면 저렇게 써있다. 직역하자면, 하둡은 안정적이고 확장 가능한 분산 컴퓨팅을 위한 오픈소스 소프트웨어이다. 프레임워크라고 보는게 조금 더 정확하긴 할듯. 그러면 이 하둡 프레임워크는 뭐뭐를 지원할까?
HDFS(Hadoop Distributed File System)
직역하면 하둡 분산 파일 시스템. 하둡에서 거대한 데이터들을 다루기 위해 사용하는 [[260422_Dev_파일 시스템|파일 시스템]]이다. HDFS는 파일을 기본적으로 64MB의 Block으로 쪼개서 여러 서버에 흩어 저장한다. 또한 서버가 죽을 수도 있으니, 똑같은 블록을 3개정도 복사해서 서로 다른 서버에 저장한다. 어떤 파일이 어디에 저장되어 있는지를 또한 특정한 서버인 NameNode에 저장한다.
위와 같은 방식으로 진행하면 특정 파일이 어떤 하나의 디스크보다 커질 수 있다는 문제도 해결할 수 있고, 서버가 갑자기 죽어도 데이터는 안전하도록 신뢰성도 보장할 수 있다.
NameNode가 죽으면 어떻게 되는가?
NameNode가 죽으면 클러스터 전체가 마비된다. 이러한 부분을 단일 장애점 (SPOF, Single point of failure) 이라고 한다. 정확히는 데이터 접근 불가 (메타 데이터가 없으니), 클러스터 좀비화 (쓰기/읽기가 중단됨), 만약 디스크 자체가 아예 파괴된 경우라면 데이터 유실 (메타데이터를 복구할 수 없으니)의 결과가 나타난다. 그래서 하둡 2.0부터는 HA(High Availability)를 도입해서 NameNode가 죽어도 즉시 서비스를 재개할 수 있도록 하는데…
MapReduce
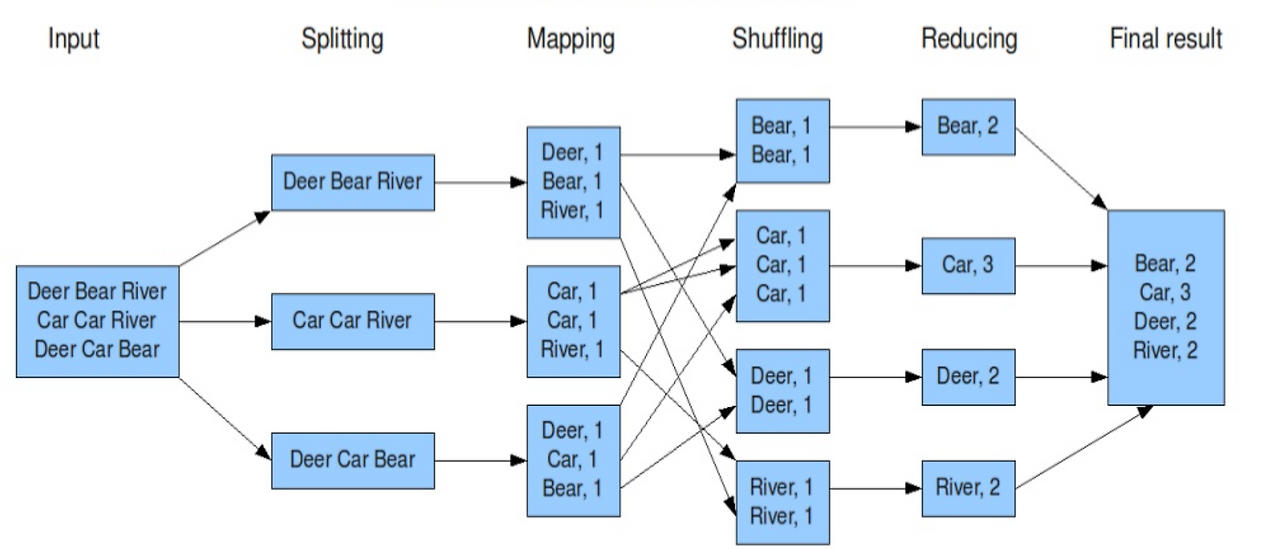 MapReduce는 하둡에서 사용하는 동적 계산 엔진이다. 대규모 배치 작업 등의 Job이 들어왔을때, 하둡은 다음과 같이 작동한다.
일단 먼저 파일들은 위에서 학습했듯 블록 단위로 나누어져서 저장되어있다. 이후 블록의 데이터들을 Key-value 쌍으로 저장하는 Mapping 과정을 수행하고, 정렬해서 연관성 있는 데이터끼리 모으는 Shuffling 과정을 수행한 후, 그 결과를 집계/요약하는 Recuding 과정을 통해 결과를 얻는다. 이후 이를 다시 HDFS의 특정 디렉터리에 파일로 저장한다.
이는 데이터를 계산 서버로 가져오지 않고 데이터가 있는 서버에서 Map Task를 실행한다는 점에서 네트워크 대역폭 낭비를 막을 수 있다!
MapReduce는 하둡에서 사용하는 동적 계산 엔진이다. 대규모 배치 작업 등의 Job이 들어왔을때, 하둡은 다음과 같이 작동한다.
일단 먼저 파일들은 위에서 학습했듯 블록 단위로 나누어져서 저장되어있다. 이후 블록의 데이터들을 Key-value 쌍으로 저장하는 Mapping 과정을 수행하고, 정렬해서 연관성 있는 데이터끼리 모으는 Shuffling 과정을 수행한 후, 그 결과를 집계/요약하는 Recuding 과정을 통해 결과를 얻는다. 이후 이를 다시 HDFS의 특정 디렉터리에 파일로 저장한다.
이는 데이터를 계산 서버로 가져오지 않고 데이터가 있는 서버에서 Map Task를 실행한다는 점에서 네트워크 대역폭 낭비를 막을 수 있다!
YARN (Yet Another Resourse Negoitator)
이번에도 직역해보자면 리소스 협상가라는 뜻인데.. 이게 무슨 소리일까? 이는 CPU, 메모리와 같은 하둡 클러스터 리소스들을 관리하고 스케쥴링 하는 하둡의 컴포넌트이다. 기본적으로 하둡은(1.0) MapReduce 작업을 할 때 정적으로 리소스를 할당했는데, 이때 Map Task와 Reduce Task의 리소스가 나누어져있다보니 한쪽만 모두 작업하고 한쪽만 놀고있는 등의 문제가 생겼다. 이에 하둡은 2.0으로 업데이트하면서 Map/Reduce 리소스(슬롯)가 별도로 존재하지 않고, 동적으로 요청된 Job에 따라 컨테이너 안의 리소스 풀에서 몇개를 땡겨올지 결정하게 되었다! 또한 하둡 1.0에서는 JobTracker이 리소스 관리와 작업 관리를 모두 진행해서 작업이 늘어나면 병목이 생겼는데, YARN을 도입하면서 ResourceManager와 ApplicationMaster 두개로 역할을 분담하면서 훨씬 더 큰 규모에서도 확장될 수 있게 되었다.
HDFS의 한계와 진화
NameNode BottleneckNameNode는 위의 HDFS 파트와 콜아웃에서도 볼 수 있듯, 모든 파일의 메타데이터를 메모리에 전부 올려놓고 운영하니 이곳이 병목이 될 수 밖에 없다! SPOF가 되는건 덤이고.
NN을 이중화, 삼중화해서 가용성을 유지하도록 하는 방법을 생각할 수 있겠다.. Active / Standby NN으로 나누는 것이다. 이 방법을 HA (High Availability), 고가용성이라고 한다.
그런데 위의 경우에서 가용성은 지켰지만, 실질적으로 쓰기 작업에서는 Active NN만 사용하므로 대역폭이나 메모리 초과 등으로 인한 쓰기에서의 SPOF 가능성이나 병목을 해결하지는 못한다. 따라서 너무 많은 메타 데이터로 인한 NN 부하를 분산시키고자 Data Node는 그대로 둔 채로 NN을 늘리는 방법을 생각할 수 있겠다. 이 방법을 federation이라고 한다.
근데 내가 원하는 데이터가 여러 NN중에 어디에 있는지 어떻게 아나? 이걸 다들고있으면 NN 하나가 다 부담하는거랑 다른게 없는데.
각 NN은 서로 다른 경로를 담당한다. NN1: /user, NN2: /data 이런식. 그리고 이 라우팅을 클라이언트한테 부담시키는 ViewFS방식, 혹은 라우터한테 부담시키는 RBF(Router-Bsed Federation) 등이 있다.
쓰기에서 NN의 부하를 줄였으니, 읽기에서도 NN의 부하를 줄여보자. 이는 먼저 NN을 Active / Standby / Observer 세개의 그룹으로 나누고, proxy provider이라는 계층을 둬서 읽기 요청이 들어왔을 때 사용할 수 있는 Observer NN으로 read를 시도하고, 모든 시도가 실패하면 그제서야 Active NN에 요청을 보내는 방식이다.
Small File Problem블록 기본값보다 훨씬 작은 파일들이 수백만개 있으면 다음과 같은 문제들이 발생한다.
- NN 메모리에 메타데이터 용량을 너무 많이 차지
- MapReduce Job이 파일 수만큼 Map Task를 생성하려 해서 오버헤드 증가
이번에도 직관적으로 생각나는 방식은 파일 여러개를 묶어서 한번에 저장하는 것이다! 이를 위해 하둡은 HAR(Hadoop Archive) 이라는 형태로, .har 확장자를 갖는 디렉토리에 큰 파일들을 묶어서 저장한다.
물론 이 안에는 _index, _marterindex, par-* 등의 파일들을 함께 저장해 원래 디렉토리 구조를 해석할 수 있는 메타파일들을 포함한다.
사실 HAR만 있는건 아닌데, key-value 쌍을 이용해서 저장하는 SequeceFile도 있다.
또한 큰 데이터들을 잘 압축해서 저장하는 방법도 같이 사용할 수 있겠다. Hadoop에서는 이를 Avro, Parquet, ORC(Optimized Row Columnar)의 세가지 파일 형식으로 보통 처리한다. 이 때 Avro는 로우 지향으로, Parquet과 ORC는 [[260409_TIL_데이터 중심 애플리케이션 설계 03 저장소와 검색|컬럼지향으로]] 데이터를 저장한다. Avro는 쓰기에 유리하고, Parquet과 ORC는 압축률과 읽기에 유리한 차이가 있다. 자세한건 저기 들어가서 보자.
Append-only, Single WriterHDFS는 기본적으로 한번 쓰면 수정 불가한 (WORM, Write Once Read Many) 모델이다. 대용량 배치 처리는 그렇다고 쳐도, 실시간 업데이트나 트랜잭션 처리는 어떻게 하면 좋을까?
사실 제일 빠른건 아무래도 다른 스토리지를 쓰는거다. Hbase, Kudu 등이 있겠다. 이쪽은 사실 잘 모른다. 나중에 공부하지 않을까?
그런데 HDFS에서도 Append 명령어를 지원하긴 한다. 데이터를 HDFS에 존재하는 파일의 마지막에 추가하고, 대상 파일이 없으면 새로 생성하는 방식인데.. 근데 원리가 찾아봐도 잘 나오지 않는다. 이것도 추후에 다시 공부하겠다. Hflush, Hsync 를 좀 찾아봐야하는 것 같다.
Hadoop과 그 다음
Spark
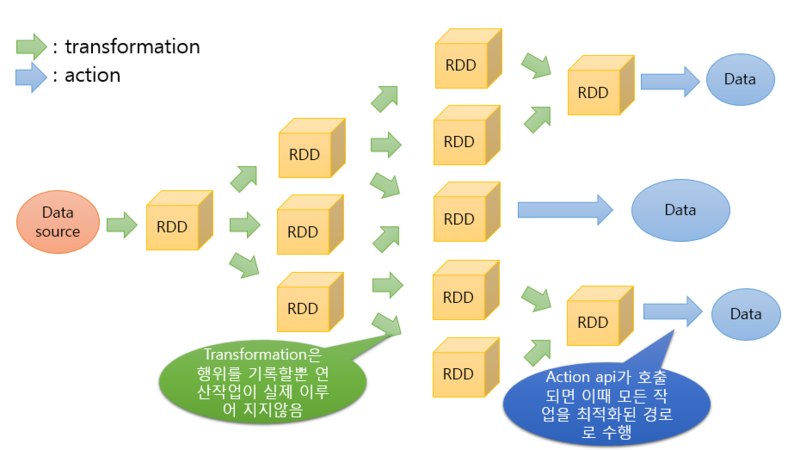
문제가 거의 다 해결된 것 같은 하둡이었지만, 아직도 문제가 없지는 않았다. 대표적으로는 MapReduce에서 각 단계 사이의 과정을 HDFS에 쓰고 다시 읽을 때 오는 디스크 IO, 혹은 이때 앞의 과정 종료를 기다리는 바운드 등이 있었다. 이에 RDD(resilient Distributed Dataset) 이라는 개념을 들고왔다. 이는 여러 분산 노드에 걸쳐서 저장되는 불변한(immutable) 데이터의 집합으로, RDD -> RDD의 Transformation 연산, RDD -> 결과의 Action 연산을 지원한다고 한다.
- 자세한 내용은 생각보다 딥해서, 조대협 멘토님의 블로그 글을 달아두겠다.
- https://bcho.tistory.com/1027 아무튼 이를 이용하다보니 중간 정보를 재사용할 수 있어서 반복/인터랙티브 연산에서 훨씬 빨라서 머신러닝/그래프 알고리즘을 활용하는 분야에서 훨씬 빠르게 동작한다!
- 물론 단일 배치 처리 등에서는 큰 차이가 없을 수도 있다.
Cloud Storage
하둡을 이해했다면 알 수 있듯이 하둡 클러스터는 스토리지와 컴퓨팅 리소스가 결합된 형태이다. 그런데, 클라우드 환경에서는 데이터가 늘어나는건 받아야하지만 Job이 없을때 리소스를 유지하고 있을 이유가 없다. 따라서 아마존 S3와 같은 오브젝트 스토리지에 데이터를 두고, 필요할때만 컴퓨트 클러스터를 띄워서 연결하는 방식도 이용할 수 있겠다.
현재 HDFS의 위치
아무튼 여러가지 이슈로 인해 HDFS 그 자체는 신규 프로젝트에선 잘 채용하지 않고 있지만, 기존 온프레미스 환경에서는 여전히 살아있고, Spark / Hive / HBase등의 파생 기술들이 모두 하둡 개념 위에 서있어서 공부할 이유는 충분하다!
여러 파생 프로젝트들을 나열만 해봐도 다음과 같다.
- 하둡에서 SQL도 날리고싶어! -> Hive, Impala
- NoSQL / 랜덤 액세스는? -> HBase, Kudu
- 스트리밍은? -> Kafka, Flink
- 워크플로우 / 오케스트레이션은? -> Airflow, Oozie
- 데이터 수집은? -> Sqoop, Flume 등등등.
하나하나 지금 당장 설명하진 않겠지만, 천천히 필요에 따라 공부하면 좋지 않을까?